Abstract
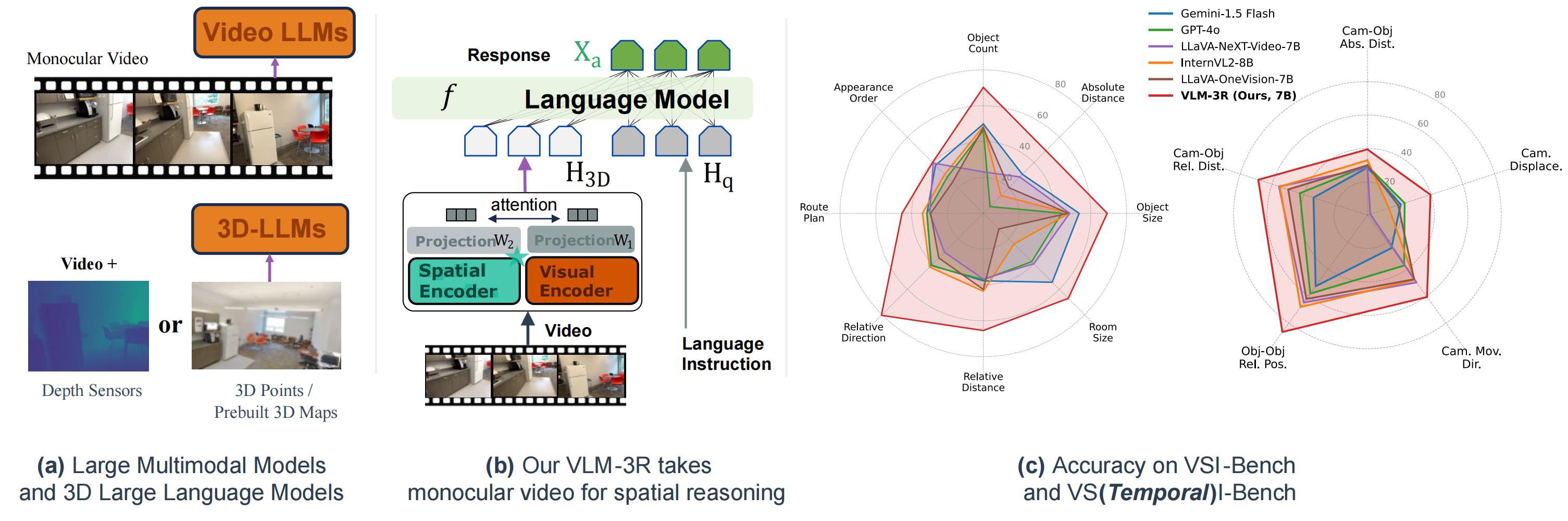
The rapid advancement of Large Multimodal Models (LMMs) for 2D images and videos has motivated extending these models to understand 3D scenes, aiming for human-like visual-spatial intelligence. Nevertheless, achieving deep spatial understanding comparable to human capabilities poses significant challenges in model encoding and data acquisition. Existing methods frequently depend on external depth sensors for geometry capture or utilize off-the-shelf algorithms for pre-constructing 3D maps, thereby limiting their scalability, especially with prevalent monocular video inputs and for time-sensitive applications. In this work, we introduce VLM‑3R, a unified framework for Vision-Language Models (VLMs) that incorporates 3D Reconstructive instruction tuning. VLM‑3R processes monocular video frames by employing a geometry encoder to derive implicit 3D tokens that represent spatial understanding. Through the utilization of our Spatial-Visual–View Fusion technique and over 200K curated 3D reconstructive instruction tuning question-answer (QA) pairs, VLM‑3R effectively aligns real-world spatial context with language instructions. This enables the model to perform monocular 3D spatial assistance and embodied reasoning. To facilitate the evaluation of temporal reasoning capabilities, we introduce the Vision-Spatial-Temporal Intelligence benchmark, featuring over 138.6K QA pairs across five distinct tasks focused on evolving spatial relationships. Extensive experiments demonstrate that our model, VLM‑3R, not only promotes robust visual-spatial reasoning but is also capable of understanding 3D contextual changes over time, excelling in both accuracy and scalability.
Overview
Key Innovations
End-to-End Monocular Video 3D Understanding
VLM-3R directly processes monocular RGB videos without needing external depth sensors or pre-built 3D maps, significantly enhancing scalability and practical applicability.
3D Reconstructive Instruction Tuning
Instruction tuning with over 200K QA pairs enables the model to effectively align visual information with 3D spatial context and language instructions.
Spatial-Visual-View Fusion
A novel fusion mechanism integrates 3D geometric tokens, per-view camera tokens, and 2D appearance features for joint spatio-linguistic understanding.
Vision-Spatial-Temporal Intelligence Benchmark (VSTI-Bench)
A new benchmark with over 138.6K QA pairs, specifically designed to evaluate the model's understanding of spatio-temporal relationships evolving from camera motion within 3D environments.
VLM-3R Architecture
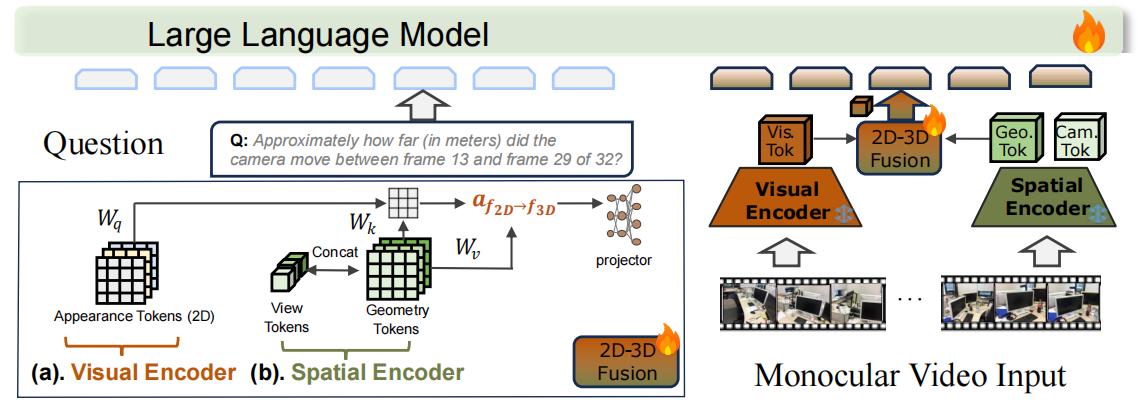
Figure: Network Architecture. Our method takes monocular video and language instruction as input. Visual Encoder coupled with Spatial Encoder extract frame-level appearance, camera view position, and globally aligned geometry. Visual-Geometry Fusion integrates these through attention and projection layers to create 3D-aware visual features for the LMM. During the inference stage, this fusion enables reliable spatial and temporal reasoning.
Architectural Overview
The core of VLM-3R is a pre-trained Large Multimodal Model (LMM), integrated with modules for deriving geometric encodings, camera view encodings, and visual features from the input video; these diverse inputs are subsequently fused effectively with language representations. VLM-3R does not rely on pre-built 3D maps or external depth sensors. This design directly addresses key limitations of existing approaches, such as the common inadequacy of Video LLMs in perceiving rich spatial context from monocular video and the restrictive dependency of many specialized 3D-LLMs on prior 3D map or depth sensor inputs.
Key Components:
- 3D Reconstructive Tokenization: Utilizes the pre-trained CUT3R model to process monocular video frame-by-frame, extracting implicit latent representations (enriched feature tokens and camera view tokens). These tokens serve as rich 3D reconstructive tokens, compactly encoding observed 3D geometry and camera perspective without relying on explicit point clouds.
- Spatial-Visual-View Fusion: Employs a cross-attention mechanism where the VLM's native visual tokens ($H_v$) attend to a unified 3D representation ($Z_{3D}$, formed by concatenated 3D feature tokens $F_{t}^{\prime}$ and camera view tokens $z_{t}^{\prime}$). The output of this attention stage ($H_{attn}$) is then residually connected with the original visual tokens ($H_{v}^{\prime} = H_v + H_{attn}$). This enriched representation $H_{v}^{\prime}$ subsequently passes through a two-layer MLP projector for alignment with the LMM.
Z3D = Concat(F't, z't)
Hattn = CrossAttention(Query: Hv, KeyValue: Z3D)
H'v = Hv + Hattn
ProjectedFeatures = MLP2-layer(H'v) - Training Objective & Fine-tuning Strategy: Adopts the same learning objective as LLaVA-NeXT-Video. To achieve efficient adaptation, Low-Rank Adaptation (LoRA) is employed for fine-tuning, which involves updating parameters within the 3D fusion attention block and the projection layers.
Datasets & Benchmarks
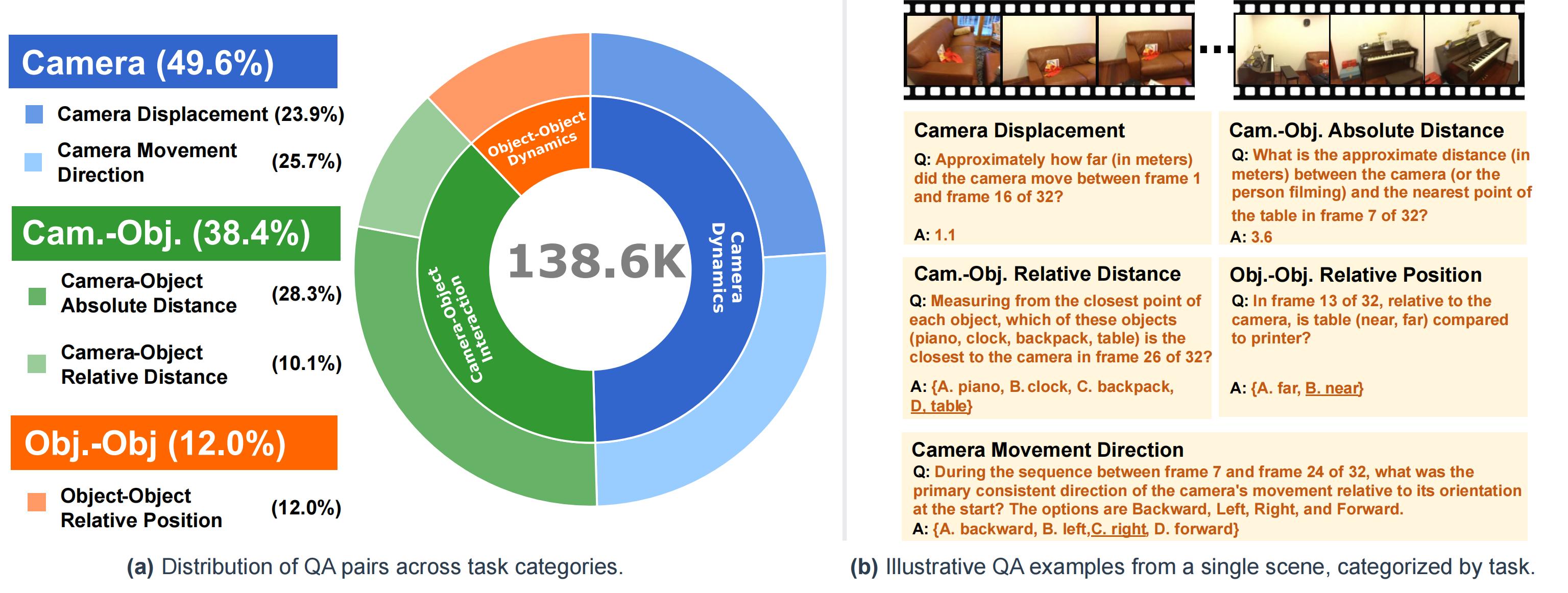
Figure: VSTemporalI-Bench Overview. (a) Statistical distribution of QA pairs by primary categories (inner ring) and their sub-categories (outer ring). (b) Example QA pairs for different task types.
Multimodal Spatial Instruction Data Generation
We developed a scalable, automated data generation pipeline to instill robust spatial intelligence in LMMs. This pipeline produced:
- Over 200,000 general question-answer pairs for spatial reasoning from monocular video.
- 4,225 embodied route planning data instances generated using simulators.
This data is derived from existing 3D datasets like ScanNet, ScanNet++, and ARKitScenes, processed via detailed spatio-temporal scene graphs to automatically generate QA pairs for tasks such as object counting, relative distance/direction, appearance order, object size, absolute distance, and room size.
Vision-Spatial-Temporal Intelligence Benchmark (VSTI-Bench)
To evaluate the understanding of dynamic 3D environments, we introduce VSTI-Bench. This benchmark contains approximately 138,600 QA pairs, distributed across three main categories: Camera Dynamics (49.6%), Camera-Object Interactions (38.4%), and Object Relative Position (12.0%). It is designed to assess LMMs' ability to perceive and reason about relative camera/object motion, dynamic object-camera relationships, and evolving spatial configurations.
Evaluation Metrics
For Multiple-Choice Answer (MCA) tasks, standard Accuracy (ACC) is used. For Numerical Answer (NA) tasks, Mean Relative Accuracy (MRA) is utilized:
VSTI-Bench: Interactive Examples





 1
1  2
2  3
3  4
4  5
5  6
6  7
7  8
8  9
9  10
10  11
11  12
12  13
13  14
14  15
15  16
16  17
17  18
18  19
19  20
20  21
21  22
22  23
23  24
24  25
25  26
26  27
27  28
28  29
29  30
30  31
31  32
32 Question 1: Approximately how far (in meters) did the camera move between frame 6 and frame 14 of 32?
Click for Answer
































































































































Experimental Results
VSI-Bench Evaluation
On VSI-Bench, VLM-3R (7B) ranks as the top-performing open-sourced Vision-Language Model, outperforming other models in its parameter class (around 7-8B) as well as those with fewer parameters. It even surpasses some significantly larger 72B parameter models and proprietary systems. This highlights the effectiveness of its reconstructive instruction tuning. The integration of spatial encoding significantly boosts LMM capabilities in distance, size, and direction estimation tasks.
| Methods | Rank | Avg. | Obj. Count | Abs. Dist. | Obj. Size | Room Size | Rel. Dist. | Rel. Dir. | Route Plan | Appr. Order |
|---|---|---|---|---|---|---|---|---|---|---|
| Numerical Answer | Multiple-Choice Answer | |||||||||
| Baseline | ||||||||||
| Chance Level (Random) | - | - | - | - | - | - | 25.0 | 36.1 | 28.3 | 25.0 |
| Chance Level (Frequency) | - | 34.0 | 62.1 | 32.0 | 29.9 | 33.1 | 25.1 | 47.9 | 28.4 | 25.2 |
| VSI-Bench Perf. († = Tiny Set) | ||||||||||
| †Human Level | - | 79.2 | 94.3 | 47.0 | 60.4 | 45.9 | 94.7 | 95.8 | 95.8 | 100.0 |
| †Gemini-1.5 Flash | - | 45.7 | 50.8 | 33.6 | 56.5 | 45.2 | 48.0 | 39.8 | 32.7 | 59.2 |
| †Gemini-1.5 Pro | - | 48.8 | 49.6 | 28.8 | 58.6 | 49.4 | 46.0 | 48.1 | 42.0 | 68.0 |
| †Gemini-2.0 Flash | - | 45.4 | 52.4 | 30.6 | 66.7 | 31.8 | 56.0 | 46.3 | 24.5 | 55.1 |
| Proprietary Models (API) | ||||||||||
| GPT-4o | 3 | 34.0 | 46.2 | 5.3 | 43.8 | 38.2 | 37.0 | 41.3 | 31.5 | 28.5 |
| Gemini-1.5 Flash | 2 | 42.1 | 49.8 | 30.8 | 53.5 | 54.4 | 37.7 | 41.0 | 31.5 | 37.8 |
| Gemini-1.5 Pro | 1 | 45.4 | 56.2 | 30.9 | 64.1 | 43.6 | 51.3 | 46.3 | 36.0 | 34.6 |
| Open-Sourced VLMs | ||||||||||
| LLaVA-OneVision-0.5B | 11 | 28.0 | 46.1 | 28.4 | 15.4 | 28.3 | 28.9 | 36.9 | 34.5 | 5.8 |
| InternVL2-2B | 12 | 27.4 | 21.8 | 24.9 | 22.0 | 35.0 | 33.8 | 44.2 | 30.5 | 7.1 |
| LLaVA-NeXT-Video-7B | 5 | 35.6 | 48.5 | 14.0 | 47.8 | 24.2 | 43.5 | 42.4 | 34.0 | 30.6 |
| InternVL2-8B | 6 | 34.6 | 23.1 | 28.7 | 48.2 | 39.8 | 36.7 | 30.7 | 29.9 | 39.6 |
| LLaVA-OneVision-7B | 7 | 32.4 | 47.7 | 20.2 | 47.4 | 12.3 | 42.5 | 35.2 | 29.4 | 24.4 |
| LongVA-7B | 9 | 29.2 | 38.0 | 16.6 | 38.9 | 22.2 | 33.1 | 43.3 | 25.4 | 15.7 |
| VILA-1.5-8B | 10 | 28.9 | 17.4 | 21.8 | 50.3 | 18.8 | 32.1 | 34.8 | 31.0 | 24.8 |
| LongVILA-8B | 13 | 21.6 | 29.1 | 9.1 | 16.7 | 0.0 | 29.6 | 30.7 | 32.5 | 25.5 |
| InternVL2-40B | 4 | 36.0 | 34.9 | 26.9 | 46.5 | 31.8 | 42.1 | 32.2 | 34.0 | 39.6 |
| VILA-1.5-40B | 8 | 31.2 | 22.4 | 24.8 | 48.7 | 22.7 | 40.5 | 25.7 | 31.5 | 32.9 |
| LLaVA-NeXT-Video-72B | 2 | 40.9 | 48.9 | 22.8 | 57.4 | 35.3 | 42.4 | 36.7 | 35.0 | 48.6 |
| LLaVA-OneVision-72B | 3 | 40.2 | 43.5 | 23.9 | 57.6 | 37.5 | 42.5 | 39.9 | 32.5 | 44.6 |
| VLM-3R (7B) | 1 | 60.9 | 70.2 | 49.4 | 69.2 | 67.1 | 65.4 | 80.5 | 45.4 | 40.1 |
VSTI-Bench Evaluation
On VSTI-Bench, VLM-3R also demonstrates strong capabilities in understanding spatial context and temporal movement, enabling it to effectively answer questions and make inferences about video content.
| Methods | Rank | Avg. | Cam-Obj Abs. Dist. | Cam. Displace. | Cam. Mov. Dir. | Obj-Obj Rel. Pos. | Cam-Obj Rel. Dist. |
|---|---|---|---|---|---|---|---|
| Numerical Answer | Multiple-Choice Answer | ||||||
| Baseline | |||||||
| Chance Level (Random) | - | - | - | - | 36.1 | 50.0 | 36.1 |
| Chance Level (Frequency) | - | 27.4 | 5.4 | 6.2 | 40.7 | 52.2 | 32.4 |
| Human Performance | |||||||
| †Human Level | - | 77.0 | 51.4 | 46.8 | 95.1 | 97.5 | 94.3 |
| Proprietary Models (API) | |||||||
| GPT-4o | 1 | 38.2 | 29.5 | 23.4 | 37.3 | 58.1 | 42.5 |
| Gemini-1.5 Flash | 2 | 32.1 | 28.5 | 20.9 | 24.4 | 52.6 | 33.9 |
| Open-Sourced VLMs | |||||||
| LLaVA-OneVision-0.5B | 9 | 36.9 | 16.5 | 32.4 | 46.1 | 50.5 | 39.0 |
| InternVL2-2B | 7 | 38.1 | 17.7 | 27.8 | 43.0 | 54.9 | 47.2 |
| LLaVA-NeXT-Video-7B | 5 | 40.0 | 28.2 | 1.8 | 49.8 | 64.7 | 55.6 |
| LLaVA-OneVision-7B | 4 | 41.7 | 29.9 | 19.3 | 47.5 | 62.1 | 49.8 |
| LongVA-7B | 10 | 32.3 | 13.5 | 5.1 | 43.7 | 57.9 | 41.2 |
| InternVL2-8B | 3 | 43.5 | 32.9 | 13.5 | 48.0 | 68.0 | 55.0 |
| LongVILA-8B | 11 | 30.5 | 20.0 | 11.6 | 35.4 | 52.3 | 33.4 |
| VILA-1.5-8B | 8 | 37.3 | 30.1 | 27.3 | 42.2 | 50.4 | 36.7 |
| VILA-1.5-40B | 6 | 38.2 | 28.2 | 15.7 | 28.8 | 65.4 | 53.0 |
| LLaVA-NeXT-Video-72B | 2 | 44.0 | 32.3 | 10.5 | 48.1 | 78.3 | 50.9 |
| VLM-3R (7B) | 1 | 58.8 | 39.4 | 39.6 | 60.6 | 86.5 | 68.6 |
Ablation Studies
Ablation studies confirm that both geometric token fusion and camera token fusion are critical to VLM-3R's performance, especially in tasks reliant on scene structure and directional awareness. The overall 3D fusion mechanism also shows clear performance benefits.
| Methods | Rank | Avg. | Obj. Count | Abs. Dist. | Obj. Size | Room Size | Rel. Dist. | Rel. Dir. | Route Plan | Appr. Order |
|---|---|---|---|---|---|---|---|---|---|---|
| Numerical Answer | Multiple-Choice Answer | |||||||||
| LLaVA-NeXT-Video ft (w/o C&G Tok.) | 4 | 57.74 | 70.64 | 43.67 | 70.82 | 63.72 | 64.93 | 68.93 | 40.72 | 38.51 |
| VLM-3R w/o Cam. Tok. | 3 | 59.09 | 69.50 | 48.66 | 68.47 | 65.21 | 62.82 | 78.86 | 42.78 | 36.41 |
| VLM-3R w/o Geo. Tok. | 2 | 59.46 | 70.30 | 49.27 | 68.36 | 66.01 | 61.27 | 81.35 | 41.75 | 37.38 |
| VLM-3R (Full Model) | 1 | 60.90 | 70.16 | 49.38 | 69.15 | 67.12 | 65.35 | 80.52 | 45.36 | 40.13 |